Date: 2024-09-01
Duration: Approximately 2 hours and 54 minutes 1
Impact: Metropolis’ server was unreachable, causing disruption to all services dependent on it
Timeline
-
6:14 PM: Routine server maintenance initiated with an
apt update && apt upgrade. -
6:24 PM: Server rebooted as part of the update process due to there being a kernel update.
-
6:27 PM: Reboot completed, but SSH access was unavailable. Attempts to connect resulted in “Connection timed out” errors.

-
6:33 PM:
- managed to gain access to the server via the recovery console
sshdservice status was checked and found to be active and running, indicating the SSH server itself was operational.pingcommands to the host failed, suggesting network connectivity issues
-
6:39 PM:
- Further attempts to diagnose the issue.
- Disabling the Uncomplicated Firewall (
ufw) had no effect, ruling it out as the cause of the connectivity problem.
-
6:42 PM:
- An attempt to install
net-toolsfailed due to the network being unreachable. - I then tried to
ping 1.1.1.1(Cloudflare’s DNS resolver) also failed, further confirming the lack of general internet connectivity was server side and not just a DNS issue
- An attempt to install
-
6:44 PM:
- A power cycle was initiated in an attempt to reset the network hardware and potentially resolve the issue
-
6:45 PM:
- After finding a an official Digital Ocean article about the issue, I tried checking
/etc/netplan/50-cloud-init.yamlonly to discover it doesn’t exist…
- After finding a an official Digital Ocean article about the issue, I tried checking
-
6:54 PM:
- After a little bit more digging,
eth1didn’t exist either - The
netplan statuscommand revealed that the primary interfaceeth0was initialized and up, yet later research found that it didn’t have a valid IP config setup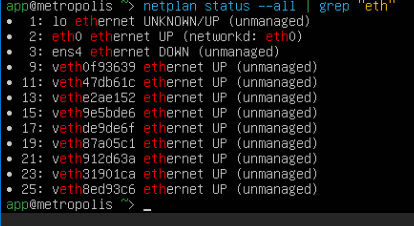
- After a little bit more digging,
-
7:02 PM:
- In an attempt to recover the missing configuration file, a backup restoration was initiated.
- The
netplan generatecommand, which should regenerate network configuration, produced unusable output, further complicating the recovery.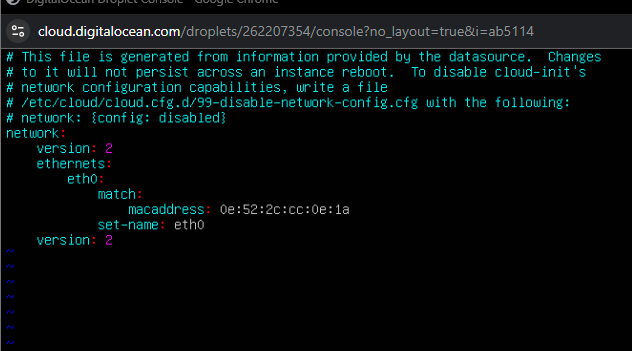
-
8:01 PM:
- A decision was made to restore from a backup, despite the potential loss of 3 days’ worth of data.
-
8:11 PM:
- The backup itself was found to be broken or unusable as they had the same issues.
-
8:18 PM:
- A final attempt to restart the networking service (
systemctl restart networking.service) failed asnetworking.servicecouldn’t be found, indicating deeper issues with the network configuration beyond just missing files.
- A final attempt to restart the networking service (
-
8:21 PM:
- With other options exhausted, booting from a recovery ISO was initiated as a potential way to access and repair the system
-
8:41 PM:
- The root cause was definitively identified: the
apt upgrade/ kernel update had inadvertently removed or corrupted the network settings.
- The root cause was definitively identified: the
-
8:50 PM:
- With the recovery ISO boot seemingly unsuccessful, the possibility of migrating to a new VPS was considered as a last resort
-
8:53 PM:
- I tried removing all
ipinterfaces (besidesdocker0) and added them back from scratch using the gateway, public IP and network mask i found in the Digital Ocean dashboardsudo ifconfig eth0 {ip} netmask {netmask} upsudo ip route add default via {gateway
- I tried removing all
-
8:58 PM:
- Network was partially up again
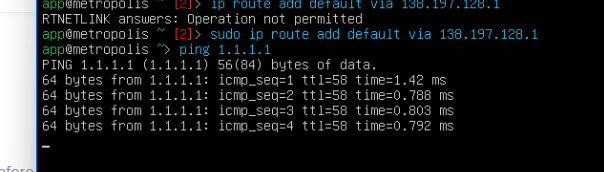
- Network was partially up again
-
9:24 PM:
- Network was fully up and all services restored.
Root Cause Analysis
The apt upgrade inadvertently altered or removed critical network configuration files, specifically /etc/netplan/50-cloud-init.yaml leading to the loss of the default routes. and the eth0 / eth1 network interfaces (eth0 being the one that connected us to the public internet). This rendered the server unreachable even though sshd was running.
Contributing Factors
- Lack of robust backup and recovery procedures: The unavailability or corruption of backups hindered recovery efforts and prolonged the outage
- Debugging on production: While the exact actions taken during troubleshooting weren’t fully captured in the logs, some comments suggest that changes were made directly on the production system, which can increase risk
Lessons Learned and Action Items
- Review and improve backup strategy: Ensure backups are regularly tested and can be reliably restored
- Implement a staging environment: Critical updates and configuration changes should be tested in a staging environment before being deployed to production
- Automate network configuration: Use tools like Ansible or cloud-init to manage network settings, making them less susceptible to accidental changes during updates
Conclusion
This incident underscores the importance of careful change management and robust recovery procedures. While the outage was eventually resolved, the associated downtime and potential data loss could have been mitigated with better preparation.
